{youtube}heMy6dlWvkQ{/youtube}
Young zebra finches are intrinsically biased to learn certain patterns of sound over others—and these patterns mirror the ones humans use, experiments show.
“In addition, these sound patterns resembled patterns that are frequently observed across human languages and in music,” says Jon Sakata, associate professor of biology at McGill University and senior author of a paper in Current Biology.
Scientists who study birdsong have been intrigued for some time by the possibility that human speech and music may be rooted in biological processes shared across a variety of animals. The new research provides new evidence to support this idea.
Linguistic inspiration
The idea for the experiments was inspired by current hypotheses on human language and music. Linguists have long found that the world’s languages share many common features, termed “universals.”
")
Two zebra finches. (Credit: Raina Fan/McGill)
These features encompass the syntactic structure of languages (e.g., word order) as well as finer acoustic patterns of speech, such as the timing, pitch, and stress of utterances. Some theorists, including Noam Chomsky, have postulated that these patterns reflect a “universal grammar” built on innate brain mechanisms that promote and bias language learning.
Researchers continue to debate the extent of these innate brain mechanisms, in part because of the potential for cultural propagation to account for universals.

At the same time, vast surveys of zebra finch songs have documented a variety of acoustic patterns found universally across populations.
(Credit: McGill)
“Because the nature of these universals bears similarity to those in humans and because songbirds learn their vocalizations much in the same way that humans acquire speech and language, we were motivated to test biological predisposition in vocal learning in songbirds,” says Logan James, a PhD student in Sakata’s lab and coauthor of the new study.
A buffet of birdsong
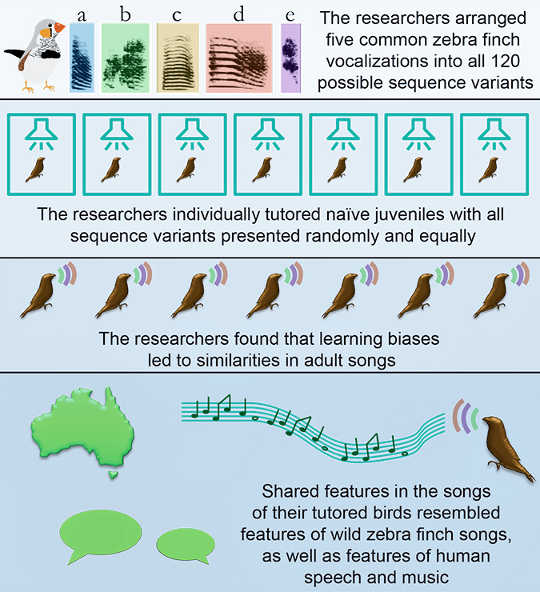
In order to isolate biological predispositions, James and Sakata individually tutored young zebra finches with songs consisting of five acoustic elements arranged in every possible sequence. They exposed the birds to each sequence permutation in equal proportion and in a random order. Each finch therefore had to individually “choose” which sequences to produce from this buffet of birdsong.
In the end, the patterns that the laboratory-raised birds preferred to produce were highly similar to those observed in natural populations of birds. For example, like wild zebra finches, birds tutored with randomized sequences often placed a “distance call”—a long, low-pitched vocalization—at the end of their song.
Other sounds were much more likely to appear in the beginning or middle of the song; for example, short and high-pitched vocalizations were more likely to be produced in the middle of song than at the beginning or end of song. This matches patterns observed across diverse languages and in music, in which sounds at the end of phrases tend to be longer and lower in pitch than sounds in the middle.
What’s next?
“These findings have important contributions for our understanding of human speech and music,” says Caroline Palmer, a professor of psychology at McGill University who was not involved in the study.
“The research, which controls the birds’ learning environment in ways that are not possible with young children, suggests that statistical learning alone—the degree to which one is exposed to specific acoustic patterns—cannot account for song (or speech) preferences. Other principles, such as universal grammars and perceptual organization, are more likely to account for why human infants as well as juvenile birds are predisposed to prefer some auditory patterns,” Palmer explains.
Sakata, who is also a member of the Centre for Research on Brain, Language and Music, says the study opens up many avenues of future work for his team with speech, language, and music researchers.
“In the immediate future,” he says, “we want to reveal how auditory processing mechanisms in the brain, as well as aspects of motor learning and control, underlie these learning biases.”
Denise Klein, director of the CRBLM and neuroscientist at the Montreal Neurological Institute, says James’ and Sakata’s study “provides insights on universals of vocal communication, helping to advance our understanding of the neurobiological bases of speech and music.”
The Natural Sciences and Engineering Research Council of Canada; the Centre for Research on Brain, Language and Music; and an award from the Heller Family Fellowship funded the research, which discussions with McGill linguists including Heather Goad and Lydia White helped shape.
Source: McGill University
Related Books:
at InnerSelf Market and Amazon

 Affairs")